5 min Recap for Andrew Ng Deep Learning Specialization-Course 3 - Structuring Machine Learning Projects
Structuring Machine Learning Projects
There can be multiple probable ideas to improve deep-learning projects.In order to narrow-down the probabilities there are some strategies to solve them.
Orthogonalization is the process of knowing which strings to pull in order to get the desired effect.For instance-
There are 4-basic objectives while building a model-
- Fit training set well on cost function.
If not ,then change the network size or change the algorithm,for instance to adams prop - Fit Dev set well on cost function.
If not ,then use regularization or bigger training set - Fit test set well on cost function.
Bigger dev set requires - Performs well on real world problem.
Single Number Evaluation Metric
While evaluating a model,if there is a single evaluation metric,which can tells that which model is more accurate then it would drastically improve efficiency of the team.
for instance

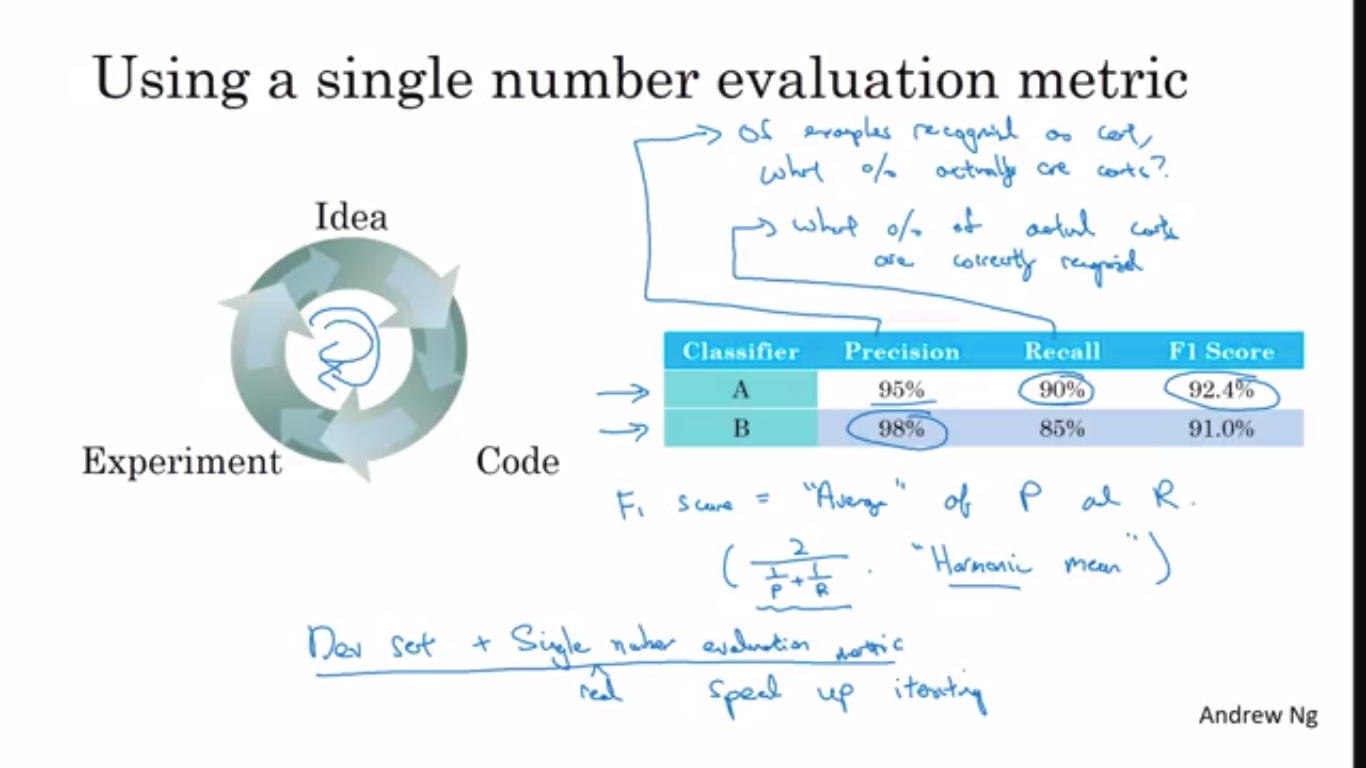
Precision-Accuracy on labelled data.
Recall-Accuracy on test data
F1-Score-It is the harmonic mean of both of the metrics and helps to identify which one to choose.
Satisfying and Evaluating Metric
Most of the time,it is difficult to find a single metric for a deep-learning model.
So,generally metrics are divided into 2 categories-
- Optimization Metric-Metric whose value one need to optimize throughout the learning process.
- Satisfying-Metric ,if its value is above the required threshold then it is not ok for the model.


Train/Dev set should be from same distribution and should be choosen such that ,one would expect to get same kind of data in future.
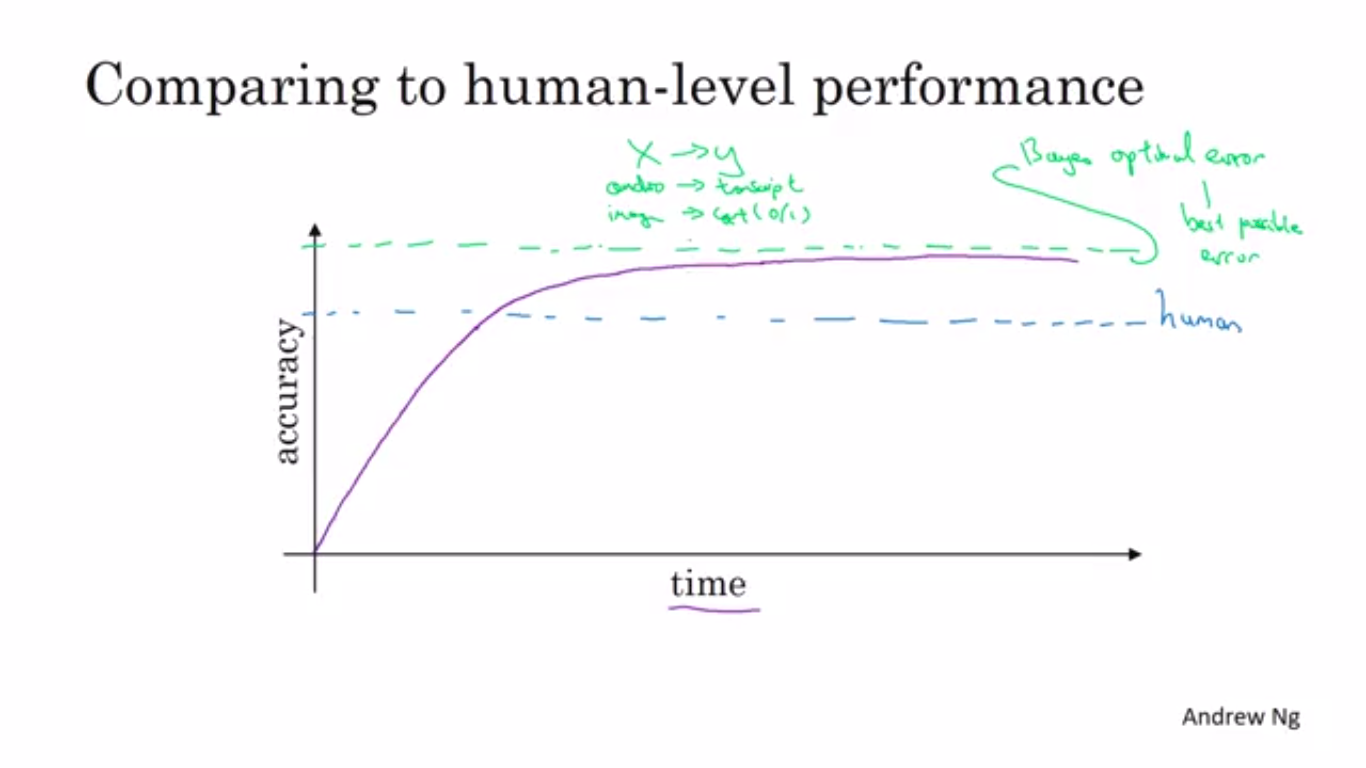
Bayes Optimal Error is the minimal theoretical error which the ML model cannot surpass in accuracy.
The tasks in which human-error is pretty low,we can use them as a proxy for bayes error.

Week-2
Error Analysis is manually examining what mistakes the algorithm is making.Instead of directing proposing a new change in model,it is wise to to error analysis by manually labelling and then checking how much improvement in error rate can be obtained.
Cleaning Up Incorrect Labelled Data
Mismatched Training And Dev/Test
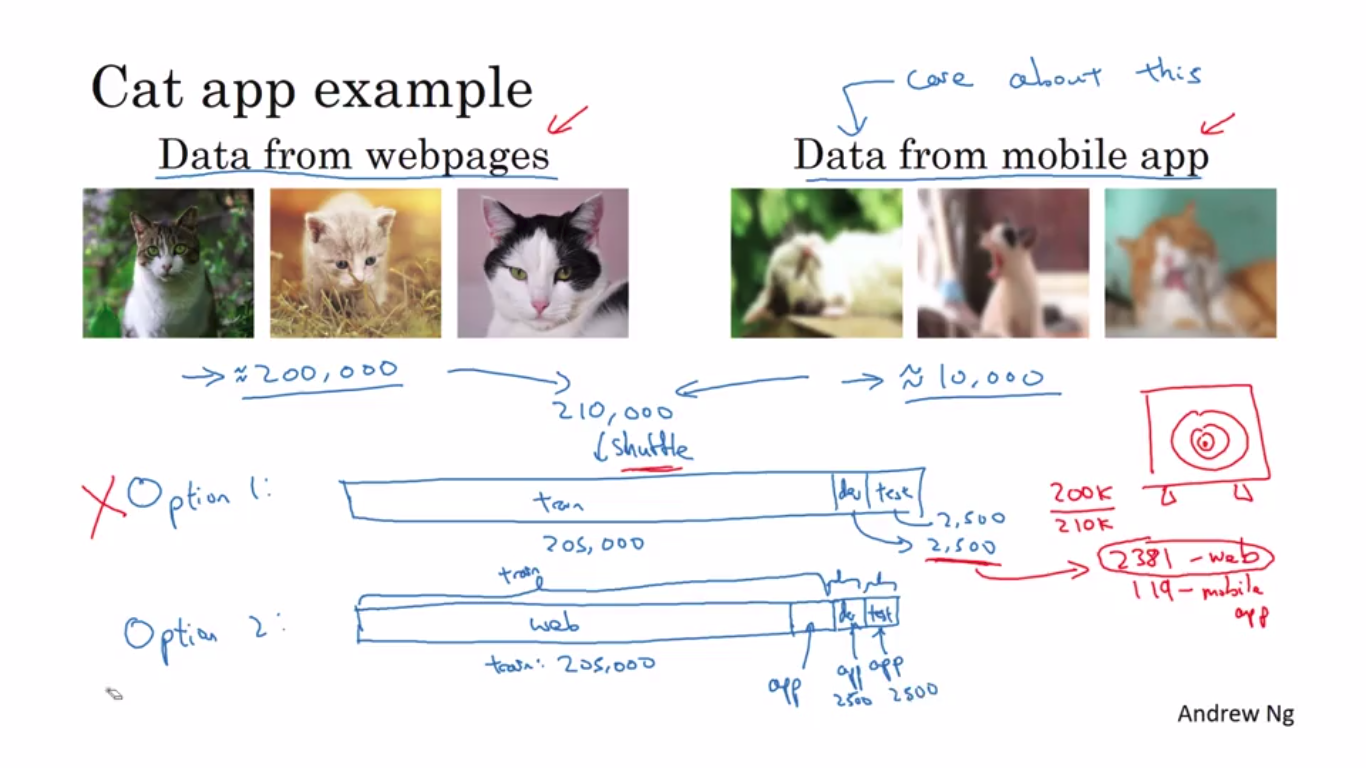
When the training and Dev/Test set distribution is different ,then instead of randomly distributing all the data across train/dev/test set,better strategy is to use a majority of data in dev/test set and (not essentially but can be) to put rest of the data in the training set.This approach is helpful when the different data is more expected after deployment phase.

Bias and Variance with Mismatched data distribution
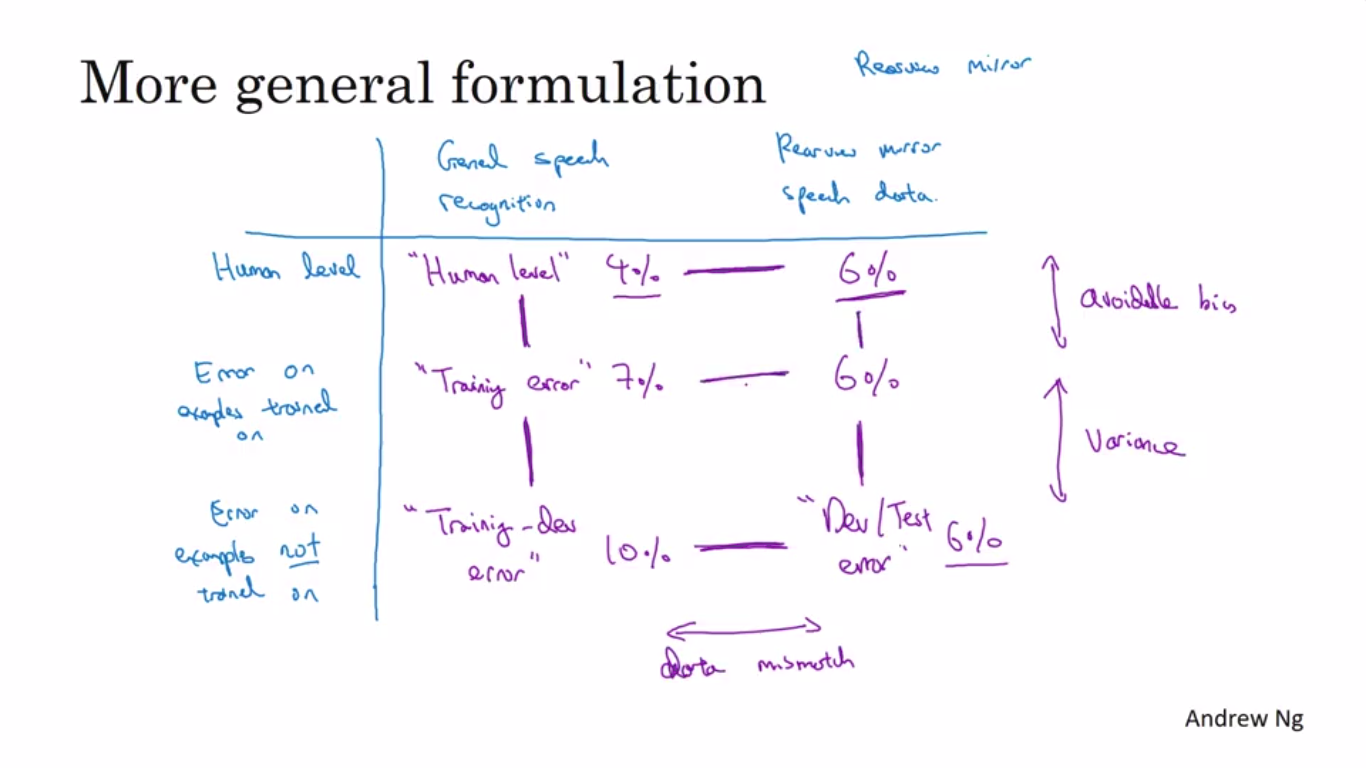
When the train and dev/test set is different then the analysation of Bias/Variance is different because if the dev error too much higher than the training error then,we are unable to figure out that ,that error is because of Variance error or data-mismatch .
To solve this problem ,we divide the training set into training-dev set and then test the data ,if the high error comes between training set and training-dev set then it is variance problem .
Otherwise ,if train/dev and dev error have high margin then it is Data mismatch problem.



Now How to solve Data Mismatch Problem
There is no systematic way to resolve the problem of Data-mismatch problem but in case of data mismatch,the first approach is to -
- Check manually between training set and test set and try to figure out the anomaly
- Then making training set similar to dev/test set y collecting more similar data or by artificial synthesis(NLP problem-car noise).


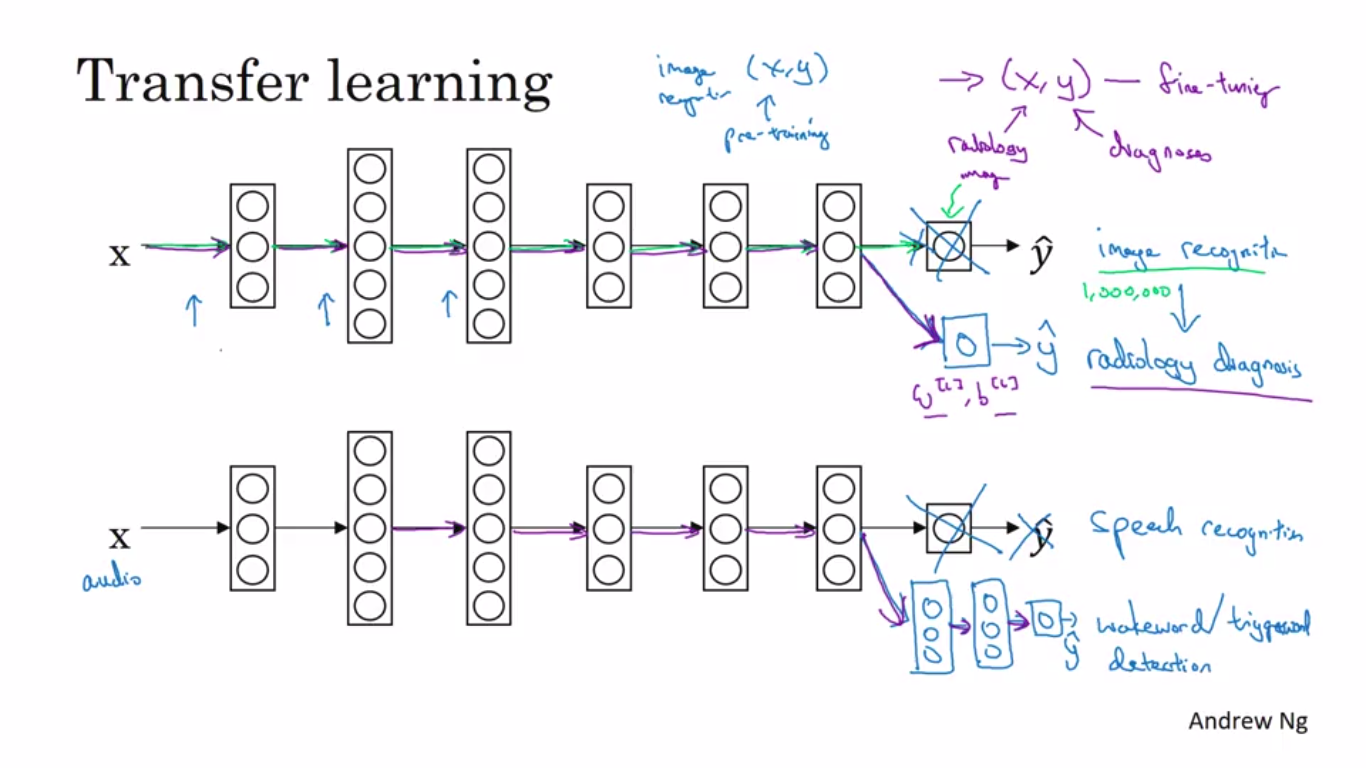
Transfer Learning
Transfer Learning is transfer of knowledge from a pre-trained task,say A to
another task which generally have less amount of data and is of same type(like images).
In it,the last layer is changes to output the task-b output.

Multi-Task Learning
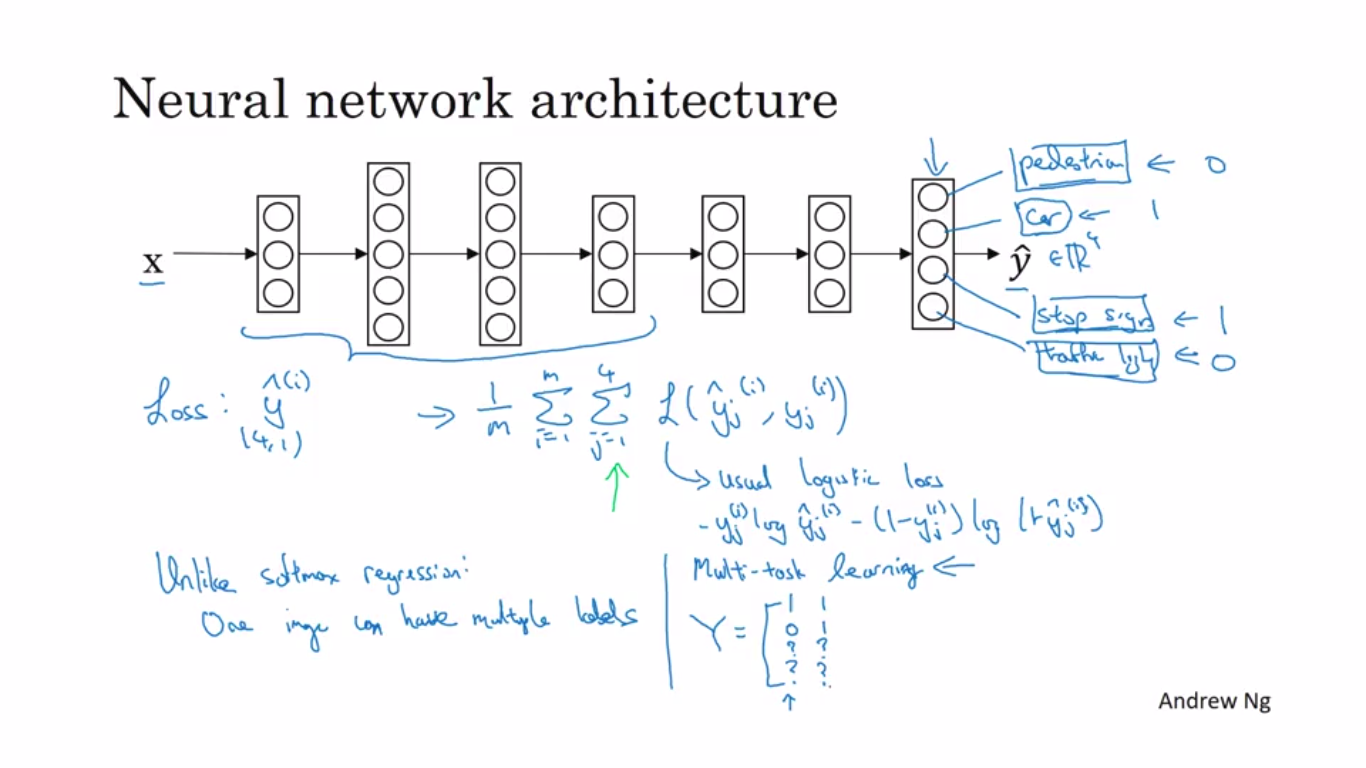
Multi-Task Learning is training of a single neural-network for doing multiple tasks instead of training several neural tasks.Beneficial in case where the multiple tasks share a commonlow-level features.
for instance ,a singe image can have multiple labels instead of one label.

End to End Deep Learning
In End to End Deep Learning ,instead of dividing a process into a multiple stages,the input data is fed into a neural network and then the desired output is obtained.
End to End Deep Learning is only useful when there is a large amount of data available.
Comments
Post a Comment