This is the mean square error representation for a binary classification neural network, in which, our model outputs only one value; as a result, the mean square error graph has only one value which is globally optimal.

While the mean square error representation for a categorical neural network, in which, our model outputs more than one value; the mean square error graph has more than one value which is locally sufficient solutions. As a result, if we use the mean square error, the problem will have no solution, and for that reason, we use the cross-entropy loss instead.

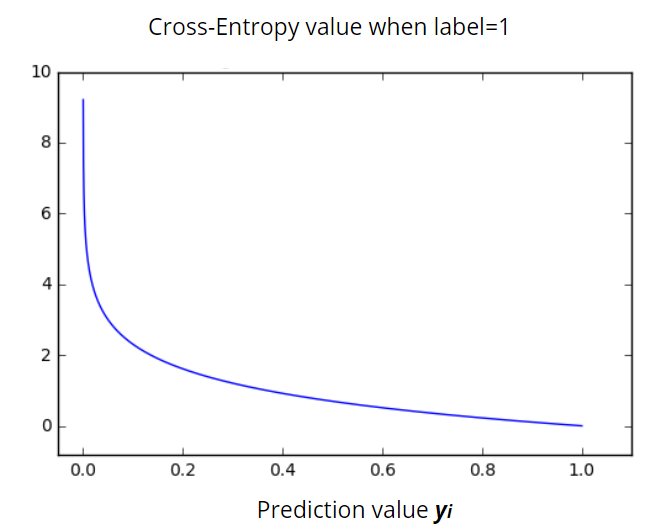
Finally, here is the cross-entropy graph:
Comments
Post a Comment