Cross-Entropy as a Loss Function
Let’s say we have a dataset of animal images and there are five different animals. Each image has only one animal in it.


Each image is labeled with the corresponding animal using the one-hot encoding.
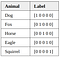

We can treat one hot encoding as a probability distribution for each image. Let’s see a few examples.
The probability distribution of the first image being a dog is 1.0 (=100%).
For the second image, the label tells us that it is a fox with 100% certainty.
…and so on.
As such, the entropy of each image is all zero.
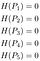
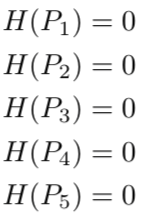
In other words, one-hot encoded labels tell us what animal each image has with 100% certainty. It is not like the first image can be a dog for 90% and a cat for 10%. It is always a dog, and there will be no surprise.
Now, let’s say we have a machine learning model that classifies those images. When we have not adequately trained the model, it may classify the first image (dog) as follows:
The model says the first image is 40% for a dog, 30% for a fox, 5% for a horse, 5% for an eagle and 20% for a squirrel. This estimation is not very precise or confident about what animal the first image has.
In contrast, the label gives us the exact distribution of the first image’s animal class. It tells us it is a dog with 100% certainty.
So, how well was the model’s prediction? We can calculate the cross-entropy as follows:
This is higher than the zero entropy of the label but we do not have an intuitive sense of what this value means. So, let’s see another cross-entropy value for comparison.
After the model is well trained, it may produce the following prediction for the first image.
As below, the cross-entropy is much lower than before.
The cross-entropy compares the model’s prediction with the label which is the true probability distribution. The cross-entropy goes down as the prediction gets more and more accurate. It becomes zero if the prediction is perfect. As such, the cross-entropy can be a loss function to train a classification model.
Comments
Post a Comment