We can improve this by using preprocessing techniques: stemming, removing stopwords, and using n-grams.
N-Grams
In the n-gram model, a token can be defined as a sequence of n items. The simplest case is the so-called unigram (1-gram) where each word consists of exactly one word, letter, or symbol. All previous examples were unigrams so far. Choosing the optimal number n depends on the language as well as the particular application. For example, Andelka Zecevic found in his study that n-grams with were the best choice to determine authorship of Serbian text documents [10]. In a different study, the n-grams of size yielded the highest accuracy in authorship determination of English text books 11] and Kanaris and others report that n-grams of size 3 and 4 yield good performances in anti-spam filtering of e-mail messages [12].

Stop Words
Stop words are words that are particularly common in a text corpus and thus considered as rather un-informative (e.g., words such as so, and, or, the, …”). One approach to stop word removal is to search against a language-specific stop word dictionary. An alternative approach is to create a stop list by sorting all words in the entire text corpus by frequency. The stop list — after conversion into a set of non-redundant words — is then used to remove all those words from the input documents that are ranked among the top n words in this stop list.
Table 3. Example of stop word removal.
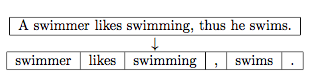
Stemming and Lemmatization
Stemming describes the process of transforming a word into its root form. The original stemming algorithm was developed my Martin F. Porter in 1979 and is hence known as Porter stemmer [8].
Table 4. Example of Porter Stemming.

Stemming can create non-real words, such as “thu” in the example above. In contrast to stemming, lemmatization aims to obtain the canonical (grammatically correct) forms of the words, the so-called lemmas. Lemmatization is computationally more difficult and expensive than stemming, and in practice, both stemming and lemmatization have little impact on the performance of text classification [9].
Table 4. Example of Lemmatization.

(The stemming and lemmatization examples were created by using the Python NLTK library, http://www.nltk.org.)
Comments
Post a Comment