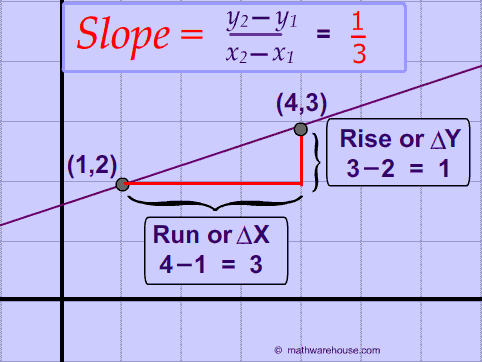
The Slope of a Line on January 10, 2020 Get link Facebook X Pinterest Email Other Apps The slope of a line means the average change rate of y with respect to x Comments
Comments
Post a Comment